近日,计算机网络与系统顶级会议USENIX NSDI 2024会议在美国加州召开,腾讯START云游戏团队与西安交通大学关于拥塞控制的最新研究论文发表在该会议上“Pudica: Toward Near-Zero Queuing Delay in Congestion Control for Cloud Gaming”,该论文由入选2022犀牛鸟精英人才计划的王世博同学作为第一作者在腾讯START云游戏团队高级研究员王婧博士和学界导师杨树森教授的联合培养下完成。
随着消费者对于数字内容体验的要求越来越高,通过本地计算来满足用户需求的难度越来越大。把数字世界的生产依托于"云端",把存储和计算密集型应用程序部署在云端,通过互联网随时随地的使用正成为行业的新趋势。最近出现的下一代互联网基础设施,如WiFi-7、5G和全光纤宽带,更是推动了基于云的应用程序的发展,其中最显著的是云游戏。得益于工业投资和学术研究的共同努力,云游戏已经在全球范围内获得了广泛的认可,同时仍在快速增长中。拥塞控制(CC)在云游戏服务中起着关键作用。然而,现有的拥塞控制方法往往会导致自身引起的瓶颈排队问题。因此,它们可能会大大延迟游戏帧传输,并削弱玩家的游戏体验。
为了解决这一难题,START云游戏团队经过多年的线上探索,提出了一种基于端到端带宽利用率估计的超低延迟云游戏拥塞控制方法Pudica。Pudica是业内第一个做到不需要增加延迟实现高带宽利用率的端到端拥塞控制算法。该算法具有极低的数据传输延迟、高带宽利用率,并且在与其他同类流竞争时能够保持跨流公平性。该研究成果已在计算机网络与系统顶级学术会议USENIX NSDI 2024上发表,会议接收文章共112篇,接受率为18.6%。
跟过去的端到端拥塞控制不同,为了实现极低的延迟,Pudica创造性的提出了一种基于带宽利用率(BUR)的估计来调整发送速率的新方法。该方法通过自适应的发送速率Pacing rate控制和补充的探测数据包,在不触发排队的同时能够实现较高精度的带宽利用率估计;基于BUR的估计,通过乘性增加的方式提升码率,能够在指数级增加链路利用率的同时,确保利用率保持在100%以下。此外,通过AI和MD同步调控的方法(AI-MD)来控制码率,Pudica能够快速收敛到跨流公平性,而不会导致严重的排队现象。除此之外,针对实际网络环境中带宽变化频繁的情况,Pudica设计了一套多时间尺度组合的,基于接收速率的降速算法,实现了网络变化时,极快的带宽跟随能力。
Pudica已经在START线上大规模部署了数年,为上千万玩家提供了服务。START的线上数据证明,Pudica实现了低排队、高带宽利用率和良好的公平性。与业界最先进的方法相比,Pudica在保持码率不变的同时,将卡顿率降低了一个数量级,并且平均帧延迟降低了3.1倍。


论文地址:https://www.usenix.org/conference/nsdi24/presentation/wang-shibo
论文题目:Pudica: Toward Near-Zero Queuing Delay in Congestion Control for Cloud Gaming
带宽利用率探测与估计
大于零的排队延迟可以作为网络瓶颈被100%利用的持续时间的可靠指标。由于目标是在帧级别几乎没有排队延迟,因此为了探测BUR,必须谨慎地引入数据包级别的排队延迟。Pudica利用每帧中的所有数据包作为一个短的Burst(即数据包列车Packet train)来探测链路带宽利用率BUR。为了提高带宽利用率估计的准确性,引入一种创新的自适应数据包间隔控制(pace控制)算法,并采用了使用少量的无负载探测数据包来检测竞争流量的辅助方法。

带宽利用率(BUR)估计。我们通过计算帧的传输延迟与物理最小延迟之间的差异来估计帧的带宽利用率:
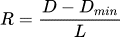 。在这里,D是单程帧延迟(one way delay),即从第一个数据包的发送时间到该帧的最后一个数据包的接收时间的间隔。Dmin使用十秒内观测到的最小数据包单程延迟作为物理最小延迟的估计,L是帧发送的间隔。
。在这里,D是单程帧延迟(one way delay),即从第一个数据包的发送时间到该帧的最后一个数据包的接收时间的间隔。Dmin使用十秒内观测到的最小数据包单程延迟作为物理最小延迟的估计,L是帧发送的间隔。
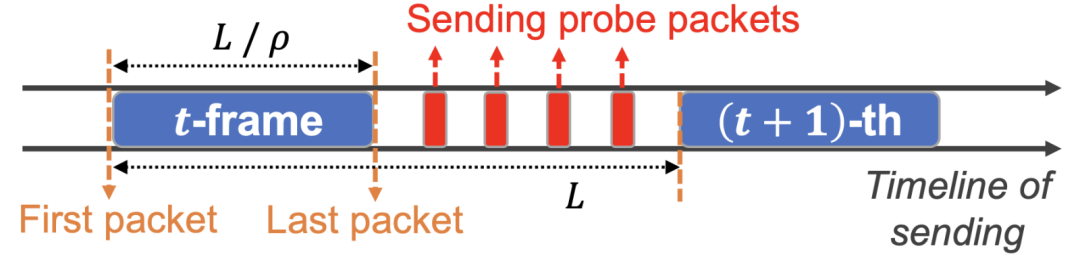
自适应数据包pacing rate控制。为了延长可感知期并保持期间链路利用率100%,发送方动态地设置pace速率的乘数,使帧中第一个数据包和最后一个数据包之间的发送间隔时间略短于排队延迟,这样在瓶颈buffer中只会引入轻微的数据包级排队。
探测包检测竞争流。为了在可感知期之后检测潜在的竞争流量,在无感知期内发Npacket个无负载的探测数据包,其间隔设置为
 ,然后,用探测数据包的反馈来增强该帧间隔内的带宽利用率,用Ti表示第i个探测包检测到的瓶颈链路排队时间,BUR估计:
,然后,用探测数据包的反馈来增强该帧间隔内的带宽利用率,用Ti表示第i个探测包检测到的瓶颈链路排队时间,BUR估计:
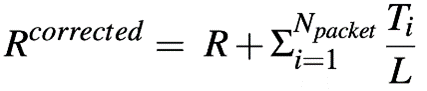 。
。
利用平滑带宽利用率进行码率调整
乘性增加(MI)提升效率。将效率控制和公平性控制解耦,当平滑BUR估计较低时,优先考虑效率而非公平性,通过使用MI来调整比特率。另一方面,当链路利用率较高但小于1时,算法的目标是在保持小于100%的高利用率的情况下向公平性收敛,这里使用阈值α来确定当前BUR属于效率控制还是公平性控制阶段,阈值α的值经验性地设置为0.85。当平滑BUR低于α时,通过乘性增加比特率以快速向效率收敛,表示为:
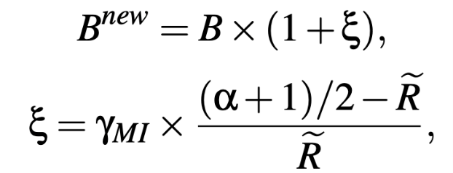
其中,γMI是乘性增加系数。需要注意的是,下一次比特率调整将被推迟到当前调整的反馈被接受之后,以防止过于激进的增加比特率,并且能够减轻比特率振荡。
同步AI-MD提升公平性。在平滑BUR超过α时,不采用传统的加性增加AI方式,即线性增加比特率直到队列建立起来。相反,通过将固定的AI步长(在经典的AI/MD框架中使用)替换为自适应步长,同时进行AI和MD比特率调整(即AI-MD):
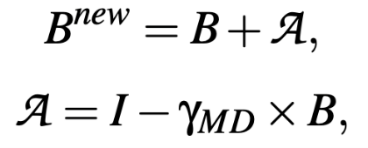
其中,I是调整步长的线性部分,γMI是乘法部分的乘性减少MD参数,在一步中同时执行AI和MD显著增加了带宽重新分配的可能性,从而加快了向公平性的收敛速度。
给定一个MD比例,固定的线性增加可能对于高带宽链路来说太小,无法充分利用带宽;或者相反,对于低带宽的链路来说,可能会导致比特率振荡和延迟频繁升高。为了解决这个困境,Pudica设计了一个AI步长自适应机制来匹配链路带宽,步长I为
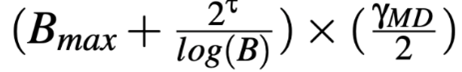 ,该公式中步长I与当前比特率B呈反相关关系,通过这种方式,高比特率的流增加得比低比特率的流慢,从而进一步加快了收敛至公平性的速度。
,该公式中步长I与当前比特率B呈反相关关系,通过这种方式,高比特率的流增加得比低比特率的流慢,从而进一步加快了收敛至公平性的速度。
MD主动清空排队。当最近接收的三帧BUR反馈都超过1时,进入主动清空排队阶段。此时,比特率设置为
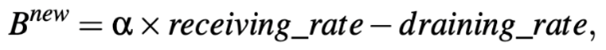 其中,receiving_rate是从拥塞开始到当前时刻的平均数据接收速率,作为在此期间可实现的最大吞吐量的可靠估计。此外,计算在接下来的200毫秒内清除自身在网络瓶颈处引起的排队所需的额外吞吐率draining_rate。这里,自身引起的排队数据量通过测量正在传输(即已发送未被ACK的数据量)来估计。主动清空排队能够高效而迅速地清空瓶颈处的现有队列。
其中,receiving_rate是从拥塞开始到当前时刻的平均数据接收速率,作为在此期间可实现的最大吞吐量的可靠估计。此外,计算在接下来的200毫秒内清除自身在网络瓶颈处引起的排队所需的额外吞吐率draining_rate。这里,自身引起的排队数据量通过测量正在传输(即已发送未被ACK的数据量)来估计。主动清空排队能够高效而迅速地清空瓶颈处的现有队列。
临时比特率回退。Pudica引入了未来延迟next delay的概念,它表示从下一个要接收的帧(即正在传输中的帧中最早发送的帧)发送的时刻到当前时刻的时间间隔。当next delay过大时,执行临时的比特率回退。引入next delay信号能够更迅速和及时地响应拥塞。这种比特率回退方案可以减少由潜在的比特率过度增加造成的排队,因为完美预测带宽利用率是难以做到的。网络存在大量抖动,抖动引起的变化可能导致错误的比特率回退,临时比特率回退的短暂性有助于最小化抖动造成的影响。
实验
Pudica已被部署在START云游戏平台上数年,为上千万玩家提供了服务,并在真实的有线和无线网络中进行了广泛的评估。大量的线上数据证明,Pudica实现了低排队、高带宽利用率和良好的公平性。
对各种BUR估计方法进行验证:Pudica的带宽利用率估计方法结合了自适应速率和探测数据包,相较于其他方法显著提高了BUR估计的准确性。

线上大规模性能测试:与业界最先进的方法相比,Pudica在保持码率不变的同时,将卡顿率降低了一个数量级,并且平均帧延迟降低了3.1倍。具体来说,在以太网网络上,Pudica将帧级平均延迟、95%尾部延迟和99%尾部延迟分别降低了1.5倍、2.4倍和3.2倍。同样,在WiFi网络上,相应的降低分别为5.7倍、7.8倍和5.5倍。Pudica在以太网网络上将100毫秒和200毫秒的阈值下的卡顿率分别降低了16.3倍和22.5倍,在WiFi网络上降低幅度为5.5倍至12.1倍。
在START云游戏平台上通过互联网(以太网)进行大规模性能测试
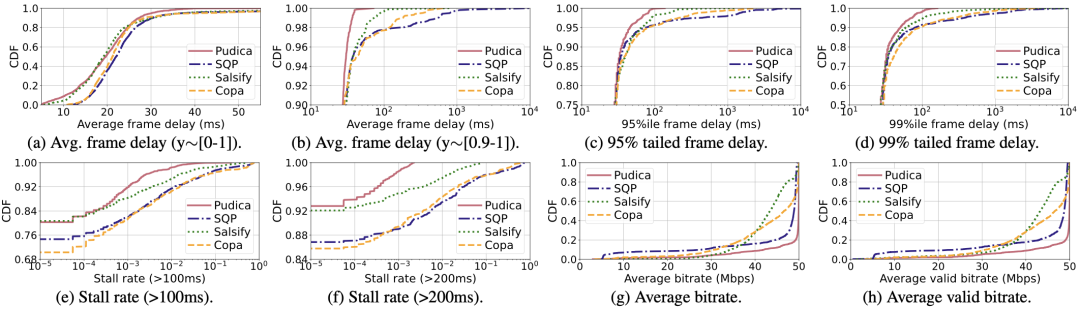
在START云游戏平台上通过互联网(无线网)进行大规模性能测试

总结:START团队经过数年时间,通过线上数据不断迭代设计了以零排队为目标的拥塞控制算法,适用于对延迟和吞吐率有严格要求的交互式流媒体场景。该算法通过一系列创新实现了业内首个同时做到“零排队”和高带宽利用率的端到端拥塞控制算法。Pudica实现了低延迟、高带宽利用率和良好的公平性,能够有效提升云游戏、VR、AR等交互式流媒体场景中的用户体验。
参考文献:
1.Wang S, Yang S, Kong X, et al. Pudica: Toward Near-Zero Queuing Delay in Congestion Control for Cloud Gaming[C]//21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). 2024: 113-129.

